Symbolic Music Generation using Recurrent Neural Networks
Master thesis project at M. Sc. IT & Cognition, University of Copenhagen.
June, 2019.
The goal of the project is to investigate how (1) datasets and (2) sequential learning mechanisms affect learning in a symbolic music generation task.
Highlights of the project:
- datasets containing a wide variety of styles are more difficult to learn from. From my experiments, I think this is because of the limited transfer learning capability between music genres (e.g. pop music is inherently different from classical)
- a model with a bidirectional LSTM outperforms a unidirectional LSTM model of the same number of parameters. This is because, in music, both positive and negative time direction contexts are of great use. Composers usually plan a melody with a known endpoint in mind.
- a model trained on a heterogenous dataset is more likely to simply reproduce (plagiarize) elements from the training set. Again, as in point (1), this is because the model fails to converge to a point where it can re-combine patterns from the music in new, original ways.
- the attention mechanism can guide the model to produce more structurally coherent pieces.
- the model trained on the music encoded in melody is better at producing more pleasing melodies than the model trained on the pianoroll encoding format.
Abstract:
The current work aims to address the task of symbolic music generation with recurrent neural networks.
I provide an overview of the state of the art techniques in the field, with a discussion of how these
techniques have been employed on this specific task. I then conduct experiments on how different factors
affect learning. I test for dataset properties (stylistic homogeneity, encoding format) and sequential
mechanisms (attention mechanism, bidirectionality). In evaluating the models I employ an objective
methodology that compares the generated samples with the training sets on multiple musical domain
statistics. I also measure the degree of plagiarism in each of the generated sets, as compared with
the training samples. I provide a discussion on how and why the mechanisms impact symbolic music
generation. I then perform a subjective analysis of the quality of the samples generated. Finally, I conduct
a user study comparing the generated sets with the training sets. The most important conclusions are: the
attention mechanism commonly employed in machine translation does improve learning in symbolic music
generation in this experiment; dataset homogeneity has a prominent impact on learning; bidirectional
LSTMs do offer an improvement; the model trained on the pianoroll format has a slightly more varied
rhythmic vocabulary than the melody counterpart.
Paper available here
Details
In my master thesis I set to investigate two main hypothesis areas:
- how does the dataset of music used to train the model affect its learning capabilities?
- How does the distribution of styles and genres within a dataset affect learning?
- How does the dataset encoding format affect learning?
- how do mechanisms for sequential, temporal learning affect the model?
- how does the attention mechanism affect learning?
- how does the bidirectional wrapper for the LSTM affect learning?
In addressing each of these questions I devise experimental setups where I change one variable (the model either includes an attention mechanism or it doesn’t) and observe the dependent variable (the quality of the results).
Architecture
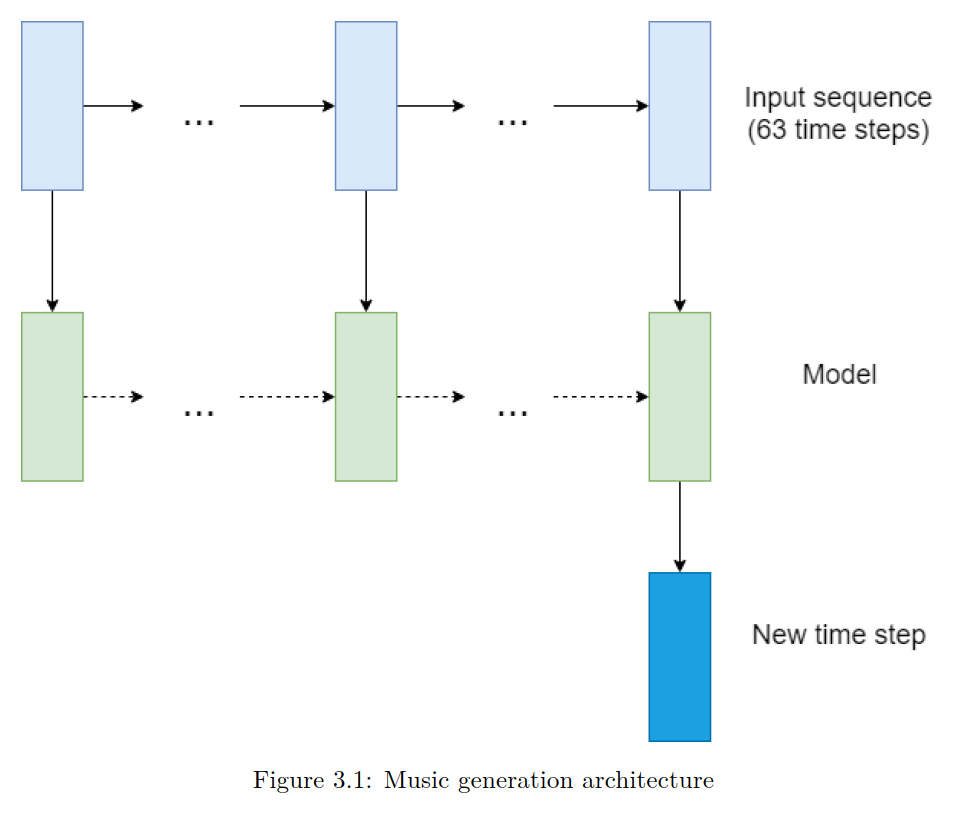
The architecture is based on RNNs with LSTM cells.
The problem we are solving is a supervised, sequential learning problem, with a many-to-one model (as per Karpathy’s classification in his blog post).
See below figure for architecture of system:
Evaluation
Since music is such a subjective topic, evaluating the success of a model is very complex.
Based on literature and musical theory, I devise four main approaches:
- Quantitative:
- I compare the generated samples from the model with the ones from the training sets, using 10 domain-based statistical features (nr. of notes per pitch class, avg. interval between notes etc.). I use KL Divergence and Area of Overlap as statistical measures.
- I employ a state of the art melodic plagiarism detection algorithm in order to obtain a metric of how much of the generated samples are simply reproductions. This is still a grey area in AI for the creative industries, where the matter of copyright and intellectual property is still to be settled. My efforts are part of this ongoing discussion.
- Qualitative:
- I conduct a user study where I ask users to rate musical snippets on a 1-5 scale. I mix 10 random samples from the training set and 10 samples from the generated samples.
- I use the model as it is envisioned to be used, i.e. to assist musicians in generating new ideas. I then perform a subjective evaluation of the results from each of the experiments.
Samples
You can hear the musical piece I wrote for the subjective analysis, along with samples generated by the models here.