Topic Classification of Controversial Subjects across Political Parties Subreddits
Project for Topics in Social Data Science course, Spring 2019.
Abstract:
The current work examines the distribution of controversial topics
across the two main parties in U.S. politics. We scrape the respec-
tive communities on Reddit and then employ topic modelling, word
embeddings, and literature research to establish a list of prevalent
topics. We then scrape the respective communities dedicated to
these topics, and build an LSTM classifier on this dataset. We
then apply this classifier on the submissions in the two political
parties’ subreddits in order to obtain a distribution of topics. We
perform a subjective evaluation of the sentences and how they are
labeled, based on the confidence scores of the network. We observe
some differences in the distribution of share of topics between the
two parties that are in line with the literature.
Full paper available here
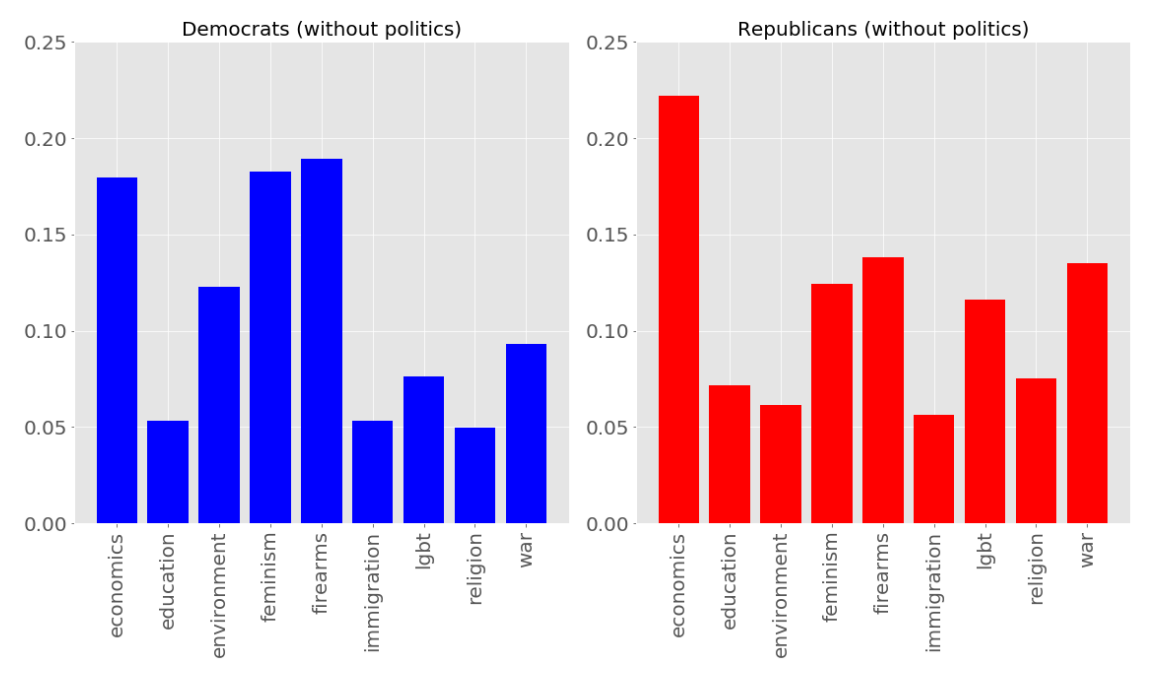
Main results in histogram form (distribution of topics across controversial submissions on reddit political communities):
Main challenges
Dataset(s)
Since we wanted to analyze controversiality we needed to find our own dataset. No such dataset exists. We thus use Reddit’s controversiality scoring mechanism to get a list of submissions (text data) across democratic and republican communities. This forms the first dataset.
Reddit also supplies our second dataset, of submissions labelled by topics. We scraped the relevant subreddits that align to our list of topics.
Another dataset-related challenge was cleaning the dataset. We observe a lot of very short submissions or submissions that point to image contents. In these cases we opt to perform OCR and extract the text.
Evaluation
Since our first dataset does not come with labels of topics we want to develop our own metrics and methods. We propose inspecting the softmax confidence scores of each prediction. This allows us to sort by the confidence value, which acts as a starting point in our subjective evaluation. We provide examples of very confident predictions and low confidence predictions.
In order to develop an objective metric we adopt the Coherence Model, in order to compare baseline models with LSTM model.
My contributions
I helped develop the main hypothesis of the project.
I scraped, collected and preprocessed the dataset(s) using the Reddit API.
I implement the baseline model using Topic Modelling algorithms (LSI, LDA, HDP) in order to detect salient topics across the submissions.
Performed Exploratory Data Analysis of corpus using word embeddings visualizations of salient topics detected in order to compile a final list of topics.
I developed the LSTM-based topic classification model.
I proposed a method of evaluating the performance of the model on classifying the Reddit submissions. We examine the softmax scores for each of the 10 classes and observe how the model can capture subtle differences across topics.
I proposed an objective evaluation metric based on Coherence Model, in order to compare baseline models with LSTM model.
Produced figures and relevant graphs for discussions.