Automatic Stance Detection using End-to-End Memory Networks
This is a re-implementation of the “Automatic Stance Detection using End-to-End Memory Networks” (source).
Group project for NLP & Deep Learning Fall 2018, IT University of Copenhagen.
The goal is to perform automatic stance detection. We use a dataset of claims and newspaper articles provided by the FakeNewsChallenge.org.
Highlight of this architecture is that it allows for it to output supporting evidence for its choices. For every prediction, we extract the relevant n-grams that form the basis for the prediction. Examples of these can be seen below.
Paper is available here.
Details
This work is part of an ongoing effort to counteract “fake news” on social media by employing Machine Learning and NLP.
The dataset consists of (headline, body, stance) instances, where stance is one of {unrelated, discuss, agree, disagree}. The model is trained to predict the
The architecture is complex and consists of multiple parts:
- input: maps the input to its representation in the memory, using word embeddings and a sparse TF-IDF representation.
- memory: contains the representations of the corpus, based on representations learned by a CNN and a LSTM.
- generalization: updates the memory with respect to new input. Consists of operations performed on the memory using similarity matrices.
- output: produces output for each new input and current memory state. Concatenates the intermediary states produced by (3).
- response: converts the output into a desired response format. Consists of a dense network that predicts the final stance.
Full architecture can be seen at the end of this post.
We can see examples of predictions and evidence snippets in the figure below:

Challenges
Dataset imbalance
The dataset was severly imbalances, as can be seen from this table.
| rows | unrelated | discuss | agree | disagree |
|---|---|---|---|---|
| 49972 | 0.73131 | 0.17828 | 0.0736012 | 0.0168094 |
In order to alleviate this we attempted undersampling and oversampling. The former proved detrimental to the overall performance of the model. The latter provided better results.
Even so, this resulted in a very low accuracy for the under-represented classes, as can be seen in this confusion matrix:
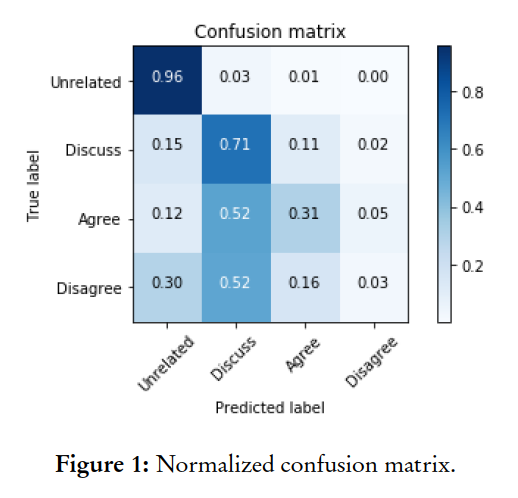
This highlights the need for higher quality datasets. As the old adage goes, “garbage in, garbage out”.
Evaluation
The dataset was originally used in a competition. Due to the imbalanced nature of it, very simple approaches (like predicting the most common class) still resulted in a high score. Thus we opt for evaluating the model on a custom point-based system which prioritizes the correct prediction of the under-represented classes.
My contribution
I pre-processed the dataset and wrote ‘glue’ code.
I collaborated on the implementation of the model, in Keras.
I produced the evidence snippets.
Full architecture
Input:
- a document (article body) segmented into paragraphs (potential pieces of evidence)
- a textual statement containing a claim (article headline)
Output:
- the stance of a document with respect to the corresponding claim (agree, disagree, discuss, unrelated)
Inference Outputs:
- k most similar paragraphs with their similarity scores
- k most similar snippets with their similarity scores
1. Input Encoding / Vectorization
Dense Representation: word embeddings pre-trained on Twitter data (GloVe)
dense body (n_samples, n_paragraphs=9, max_paragraph_len=15, embedding_dim=100)
dense claim (n_samples, max_claim_len=15, embedding_dim=100)
Sparse Representation: term frequency–inverse document frequency
sparse body (n_samples, n_paragraphs=9, vocab_size)
sparse claim (n_samples, vocab_size)
2. Memory Representation
dense body ---> TimeDistributed (LSTM, 100 units) -----------> lstm body (n_samples, 9, 100)
dense body ---> TimeDistributed (CNN, 100 filters, size 5) --> cnn body (n_samples, 9, 11, 100)
cnn body -----> MaxOut --------------------------------------> cnn body (n_samples, 9, 11)
dense claim --> LSTM (100 units) -----------> lstm claim (n_samples, 100)
dense claim --> CNN (100 filters, size 5) --> cnn claim (n_samples, 11, 100)
cnn claim ----> MaxOut --------------------------------------> cnn claim (n_samples, 11)
3. Inference and Generalization
sparse body x sparse claim ---> p tfidf (n_samples, 9) # similarity matrix
lstm body * p tfidf ----------> lstm body # memory update
lstm body x lstm claim -------> p lstm (n_samples, 9) # similarity matrix
cnn body * p lstm ------------> cnn body # memory update
cnn body x cnn claim ---------> p cnn (n_samples, 9) # similarity matrix
4. Output Memory Representation
concatenate [ mean(cnn body),
max(p cnn), mean(p cnn),
max(p lstm), mean(p lstm),
max(p tfidf), mean(p tfidf) ] --> output
5. Final Response (Class Prediction)
concatenate [ output, lstm claim, cnn claim ] --> response
response ---> MLP (300 units, relu) ------------> response
response ---> DropOut (0.5) --------------------> response
response ---> MLP (4 units, softmax) -----------> prediction
6. Inference Outputs
- a set of evidences (paragraphs) with similarity scores
- a set of snippets from the most similar paragraph with similarity scores